You can’t train a frontier model. You can’t even fine tune one. For you, “max effort” means the maximum effort you are allowed to use—not the maximum effort that’s technically possible. You are a consumer of inference provided through an API, not the owner of a top AI lab.
So what will you do? Will you settle for the access to intelligence that you currently have, or will you fight for more?
Tokenmaxxing is your way out. By massively increasing your consumption of tokens, you can scale the capabilities of the underlying models that serve them.
In this guide, we explain why this works and provide tips on how you might apply it productively to your work. But first, let’s look at how scaling compute leads to more intelligent models.
Scaling Laws
Modern LLMs are built and deployed in stages.
First, AI labs train a base model through pre-training, often followed by mid-training or continued pre-training to refine capabilities such as reasoning, coding, long-context handling, or domain knowledge.
Second, they perform post-training, using methods such as supervised fine-tuning, preference tuning, reinforcement learning, and safety tuning to improve instruction-following, alignment, reliability, and task performance. After this stage, the AI is ready to deploy.
Third, the deployed model produces answers through inference, where the trained weights are used to process a user’s input and generate output.
💡 Scale increases the quality of the result at every phase of AI development and deployment.
Sam Altman describes this eloquently in his 2025 blog post, Three Observations:
The intelligence of an AI model roughly equals the log of the resources used to train and run it. These resources are chiefly training compute, data, and inference compute. It appears that you can spend arbitrary amounts of money and get continuous and predictable gains; the scaling laws that predict this are accurate over many orders of magnitude.
We will explore this a bit more in detail for each phase of the AI development and deployment process.
Train-Time Compute
At train-time (pre-training and mid-training), the result couldn’t be more clear. If you have a bigger data center, you can produce a better model. This was convincingly established by Kaplan et al., “Scaling Laws for Neural Language Models”.
Post-Training Compute
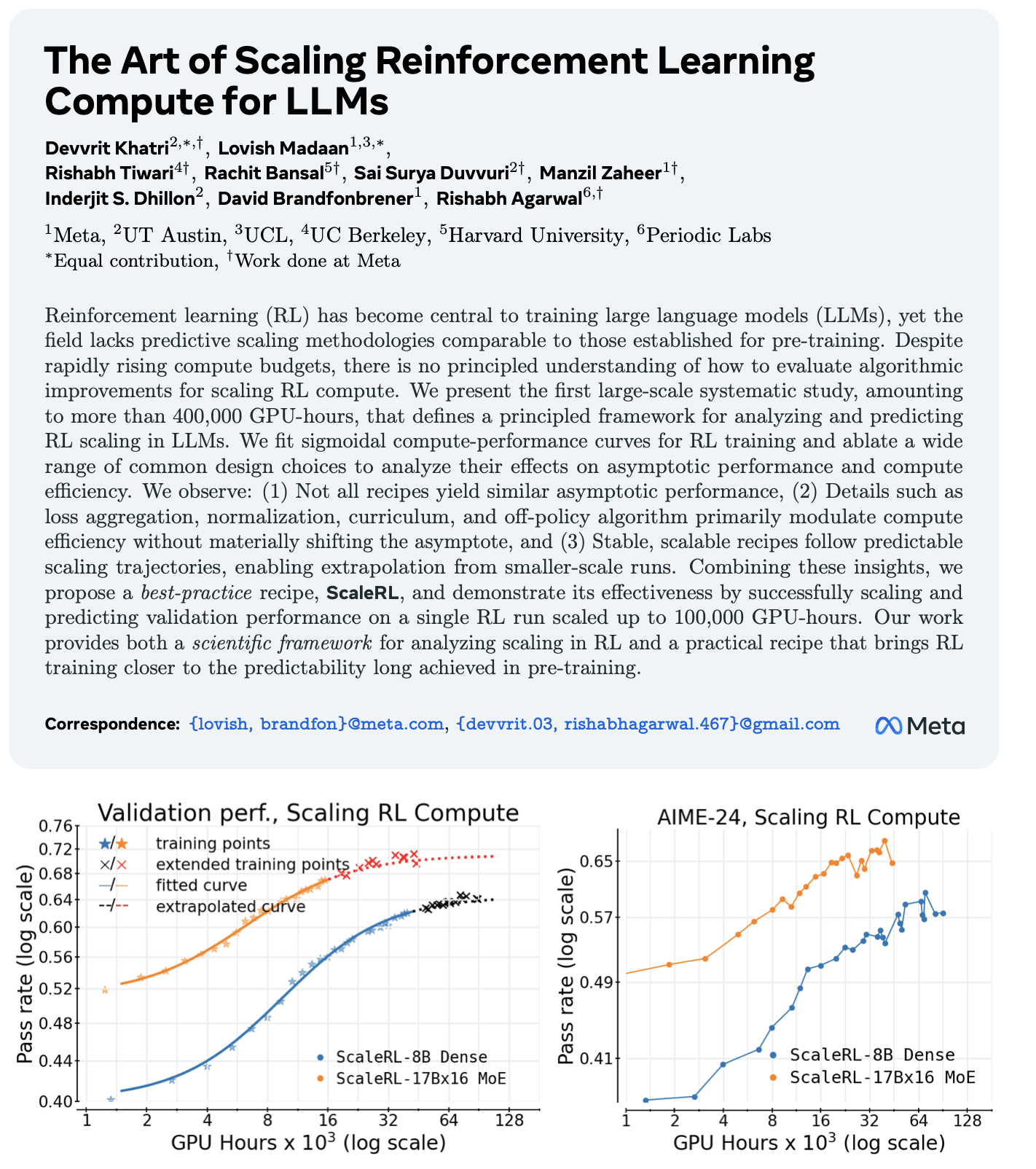
During post-training, intelligence also scales with compute—although it is worth mentioning that this process is multi-factorial and has a variety of other bottlenecks, such as the quality of the reward signal. Nevertheless, the results are clearly shown by Khatri et al., “The Art of Scaling Reinforcement Learning Compute for LLMs”.
Test-Time Compute
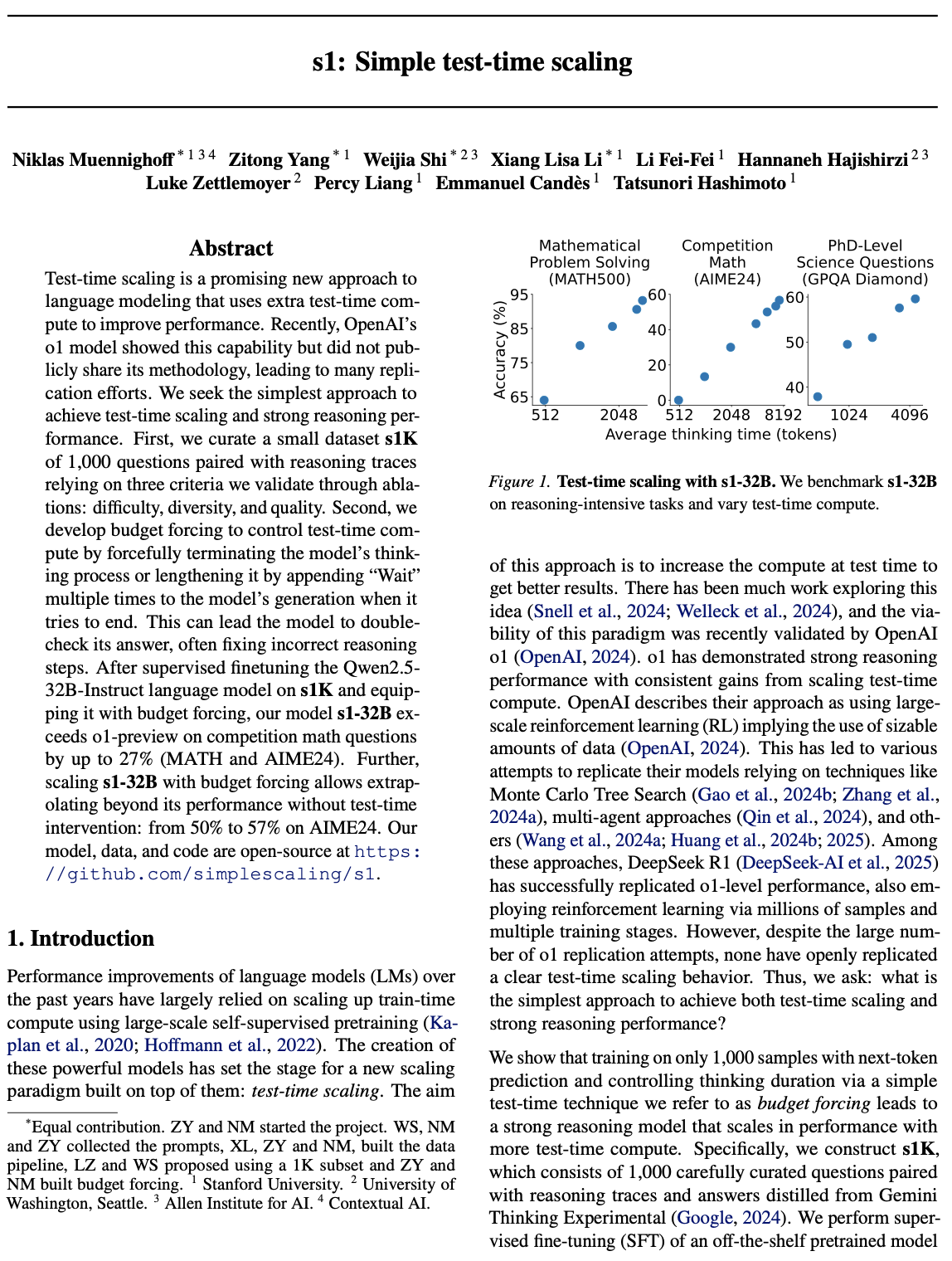
Test-time compute, also known as inference-time compute, is the process of using more compute during inference—which can actually improve the quality of the output of a model that is already trained. This form of scaling is explained well in Muennighoff et al., “s1: Simple test-time scaling”.
This is core to the difference between ChatGPT Instant, Thinking and Pro.
Although there may be differences between the underlying model weights, fundamentally Pro thinks much longer than the other modes. In essence, it generates more tokens and, by scaling its token usage, it produces a better result.
The following graph was published when OpenAI released their o-series reasoning models, a precursor to the latest ChatGPT 5.5 series.
As you can see, using the same model (o3), they were able to increase the score on a the ARC-AGI benchmark by simply increasing the compute budget. Although their exact reasoning methods are proprietary, a large portion of these gains come from simply allowing the model to “think longer” by generating more tokens before arriving at a final result.
With that said, test-time compute is very broad and labs are constantly working on more sophisticated methods. Later in this guide, we will discuss DeepMind’s AlphaEvolve, which they also frame as a test-time scaling method.
But we can draw an important distinction between AlphaEvolve and ChatGPT’s Pro reasoning.
Both implement test-time scaling, but ChatGPT Pro does so on the provider’s side while AlphaEvolve does so on the consumer’s side. In other words, DeepMind implemented AlphaEvolve by wrapping a harness around standard Gemini models. For AI researchers, this distinction is not very important. But for consumers like us, this makes all the difference in the world.
The core insight is we would like to offer is that you can scale test-time compute yourself, as a consumer.
There is ample evidence to prove that this works, which we will explore later in this guide.
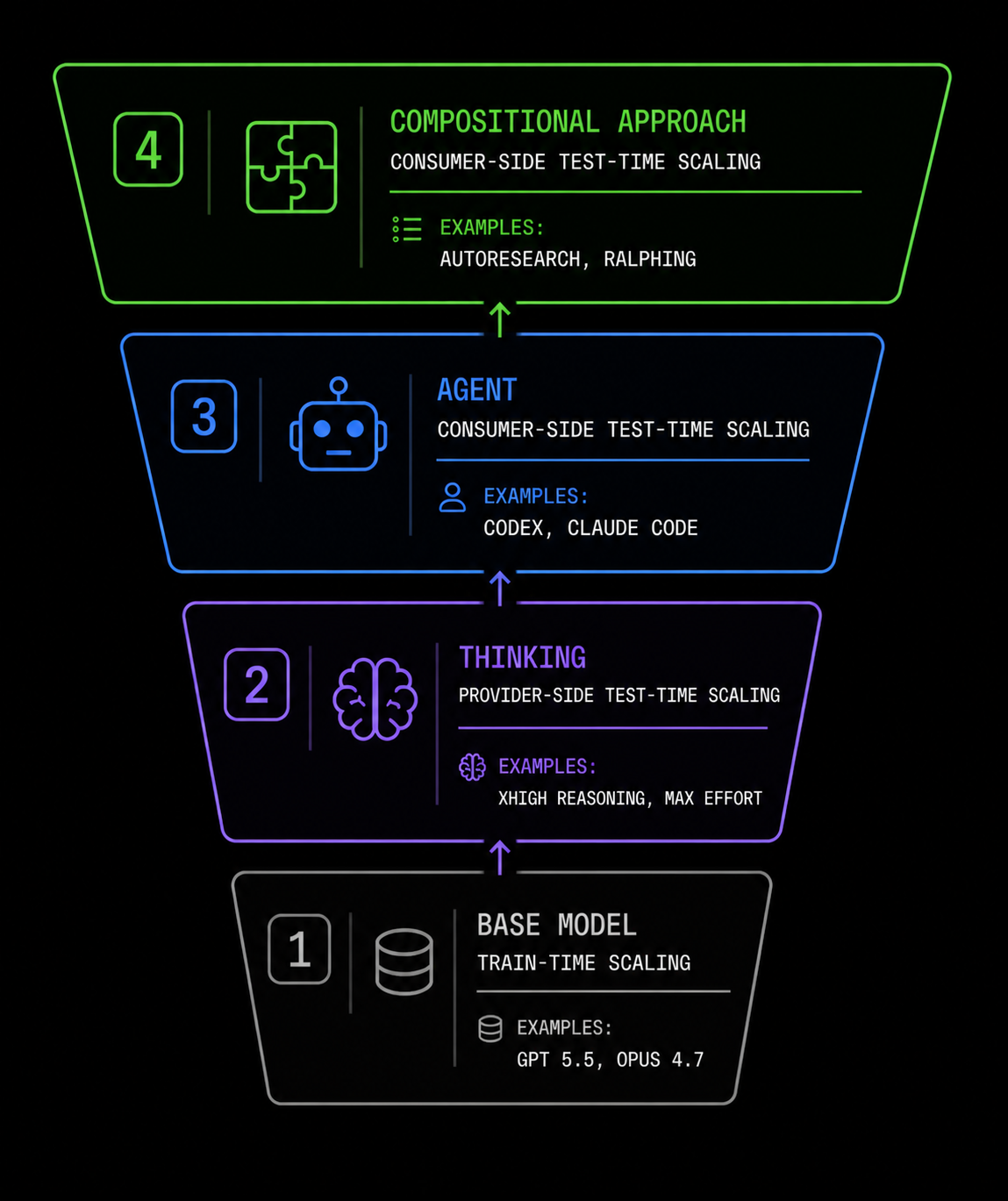
Consumer Test-Time Scaling
Consumer-side test-time scaling is the process of increasing how much inference you use, as a consumer. In other words, it is tokenmaxxing.
It can be measured by increasing what we sometimes refer to as harness-time compute, which is calculated as the average amount of compute per inference call times the number of calls you make to achieve a single result.
You can intuitively think about it like this: Since a single inference call will have a limited compute budget, wrapping that inference call in a harness that makes multiple inference calls can essentially force an AI to continue thinking.
In the previously shown o-series benchmark chart, o3-high had 172x the compute of o3-low. Now think about this: might it be possible for one to approximate o3-high level results by calling o3-low 172+ times to check its own work? This has not been explicitly demonstrated, but there is a good reason to believe that a properly designed consumer-side test-time scaling system could achieve something to this effect. We will explore the evidence for this in the next section.
The Churning Technique
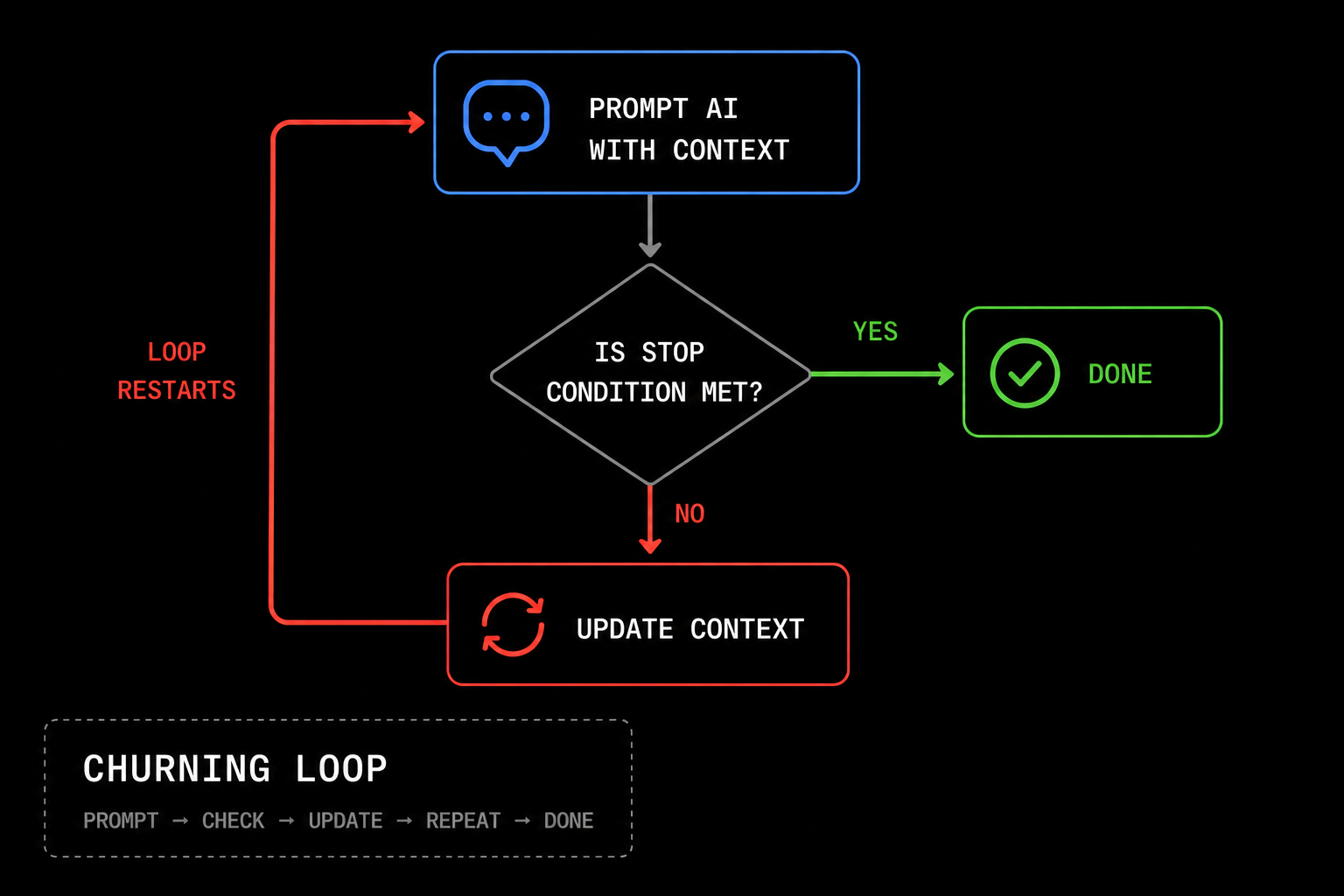
One of the best ways to scale consumer-side test-time compute is through a general process we call churning.
Churning is traditionally a process of mixing milk until it produces butter.
Doing one rotation with a hand-crank churn will not produce butter, but after 1000 rotations it will.
In the context AI, churning is the process of asking AI to do the same thing 10, 100, or possibly even 1000 times. In doing so, it eliminates the problems in its work product and produces butter—uh, I mean better—results. Through each iteration, the core prompt usually remains constant, while providing the model with updated context so that it can build on its past work.
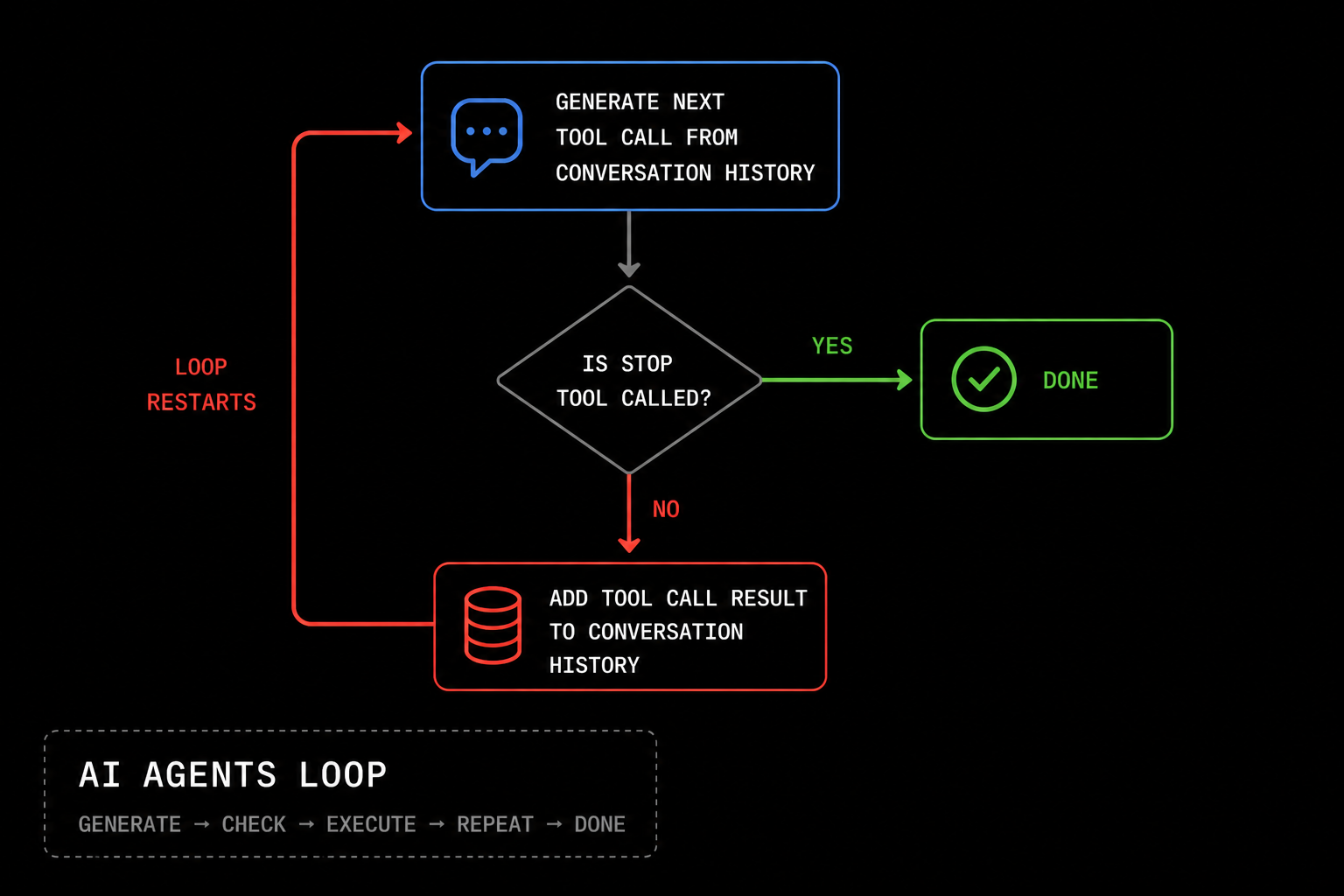
Ask yourself this: why do you use Claude Code and Codex instead of asking ChatGPT Pro to one-shot your app? It’s obviously because agents generate superior results.
We would argue that agents work by churning.
If you think about it, an agent basically runs inference in a loop, continuously adding to the context so that the next inference call can check its past work and correct its mistakes.
While reasoning models employ many techniques to keep their test-time chain-of-thought on track, agents are constantly grounding their work in the real world by testing, type checking, and compiling your app.
This ultimately explains why Yann LeCun’s concern about compounding error in autoregressive models doesn’t prevent agents from completing tasks with very long threads.
When an agent gets off-track, real deterministic tool call results collapse the error.
Agents are the clearest example of churning today, but we will argue that it is possible to employ this technique in other contexts as well.
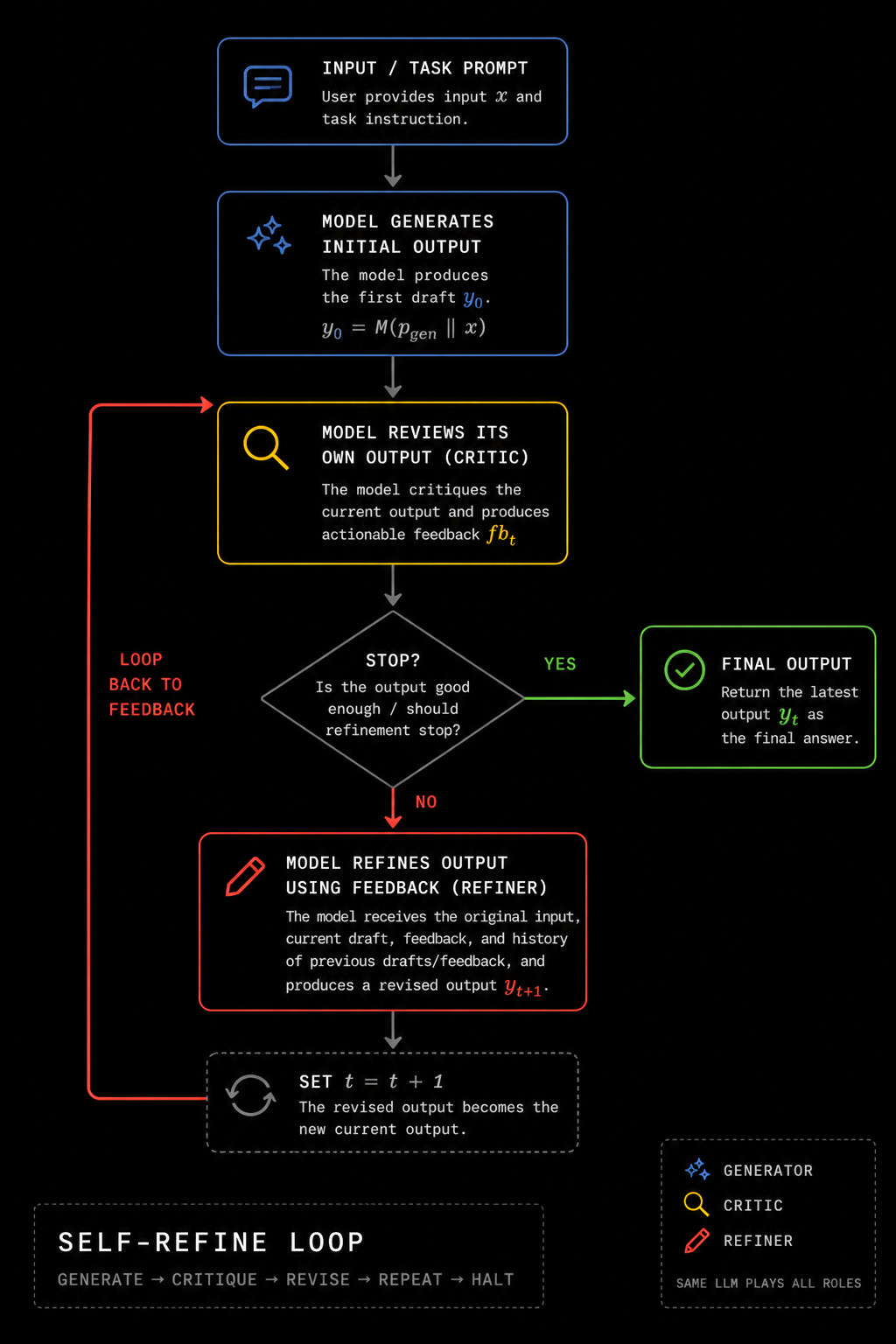
They ran a fully autonomous review process where an LLM gave itself feedback and then took that feedback to refine its previous answer in a loop.
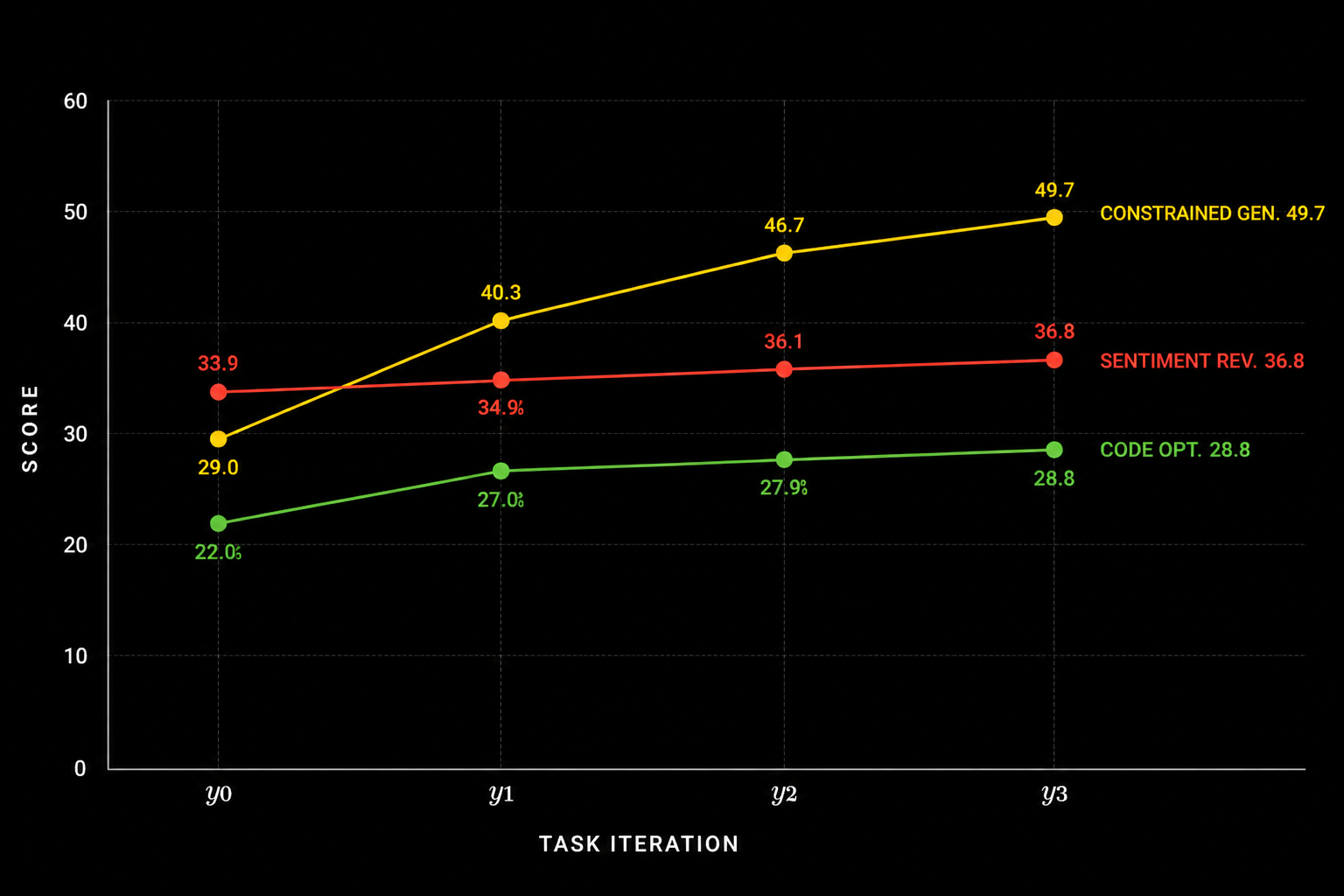
This improved the performance of the LLM across all tasks, with an average benefit of 20% from 4 iterations. While they did notice diminishing returns, it is worth noting that all forms of compute scaling (train-time, post-training, and test-time) face diminishing returns whenever they are measured.
Based on their published data, we created a chart to visualize the improvements for each type of task across each iteration.
Certain tasks clearly are more suitable to this specific approach than others, but every task they tested benefited from more iterations nonetheless.
In some ways, this is a naive and suboptimal approach. It is likely possible that there are better ways to churn results for any given task, but the exciting part about this is that this generalizes well across all tasks.
So What?
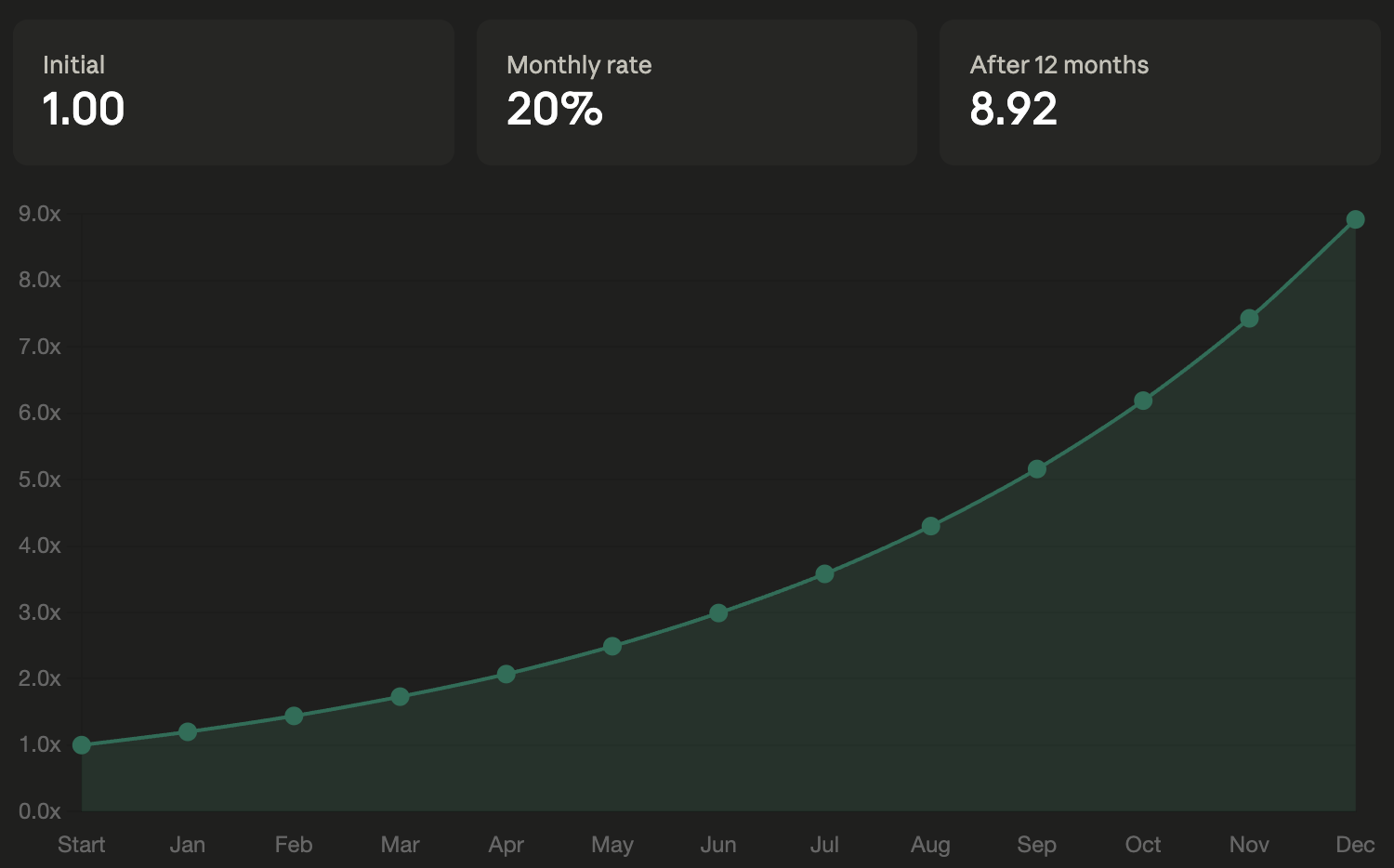
To build an intuition for why this is powerful, imagine if you ran this generic, fully automated process on every inference call you made. Your inference costs would ~9x (the original prompt + 4 iterations of one feedback prompt and one review prompt), but on average you would benefit by getting 20% better results. In our previous article How Startups Can Beat Big AI Labs, we discuss why a fixed cost increase is usually worth accepting for a compounding benefit.
…scaling AI usage to produce a better result is worth paying more for despite the fact that it has diminishing returns.
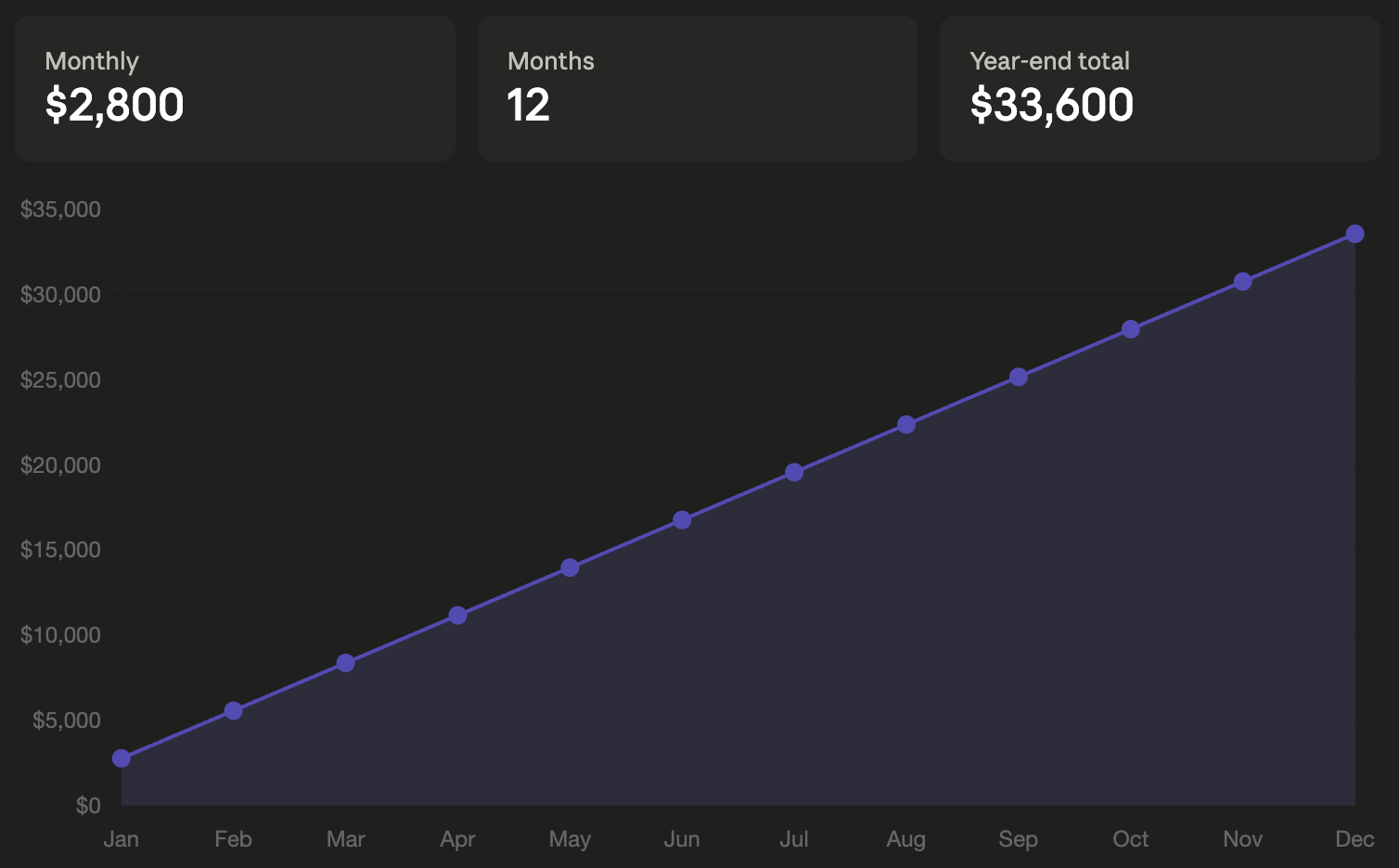
…the cost and value scale with different curves. Cost increases linearly, you pay a fixed amount more each month. If your plan is priced at $3000, compared to the $200 plan, that is $2800 extra in cost per month. So in January the company pays $2800 more, in February it increases to $5600… and by December the total reaches $33600. This is just a fraction of an engineer’s salary.
But a 20% better result compounds. Productive work builds on past work and technical debt grows exponentially. In January the product is 20% better, in February it is 44% better… and in December it is 892% better.
Compositional Approaches
Test-time scaling methods are composable.
Agents themselves use reasoning models while scaling further by churning. And that’s not even the end of the story.
A new class of consumer-side test-time scaling has recently emerged as a layer that wraps around agents. It turns out that you can ask agents to work on the same problem many times—and doing so often vastly improves their capabilities.
Properly scaling any part of this stack should amplify the performance of the other parts.
So let’s explore how we can churn on this top layer.
Autoresearch
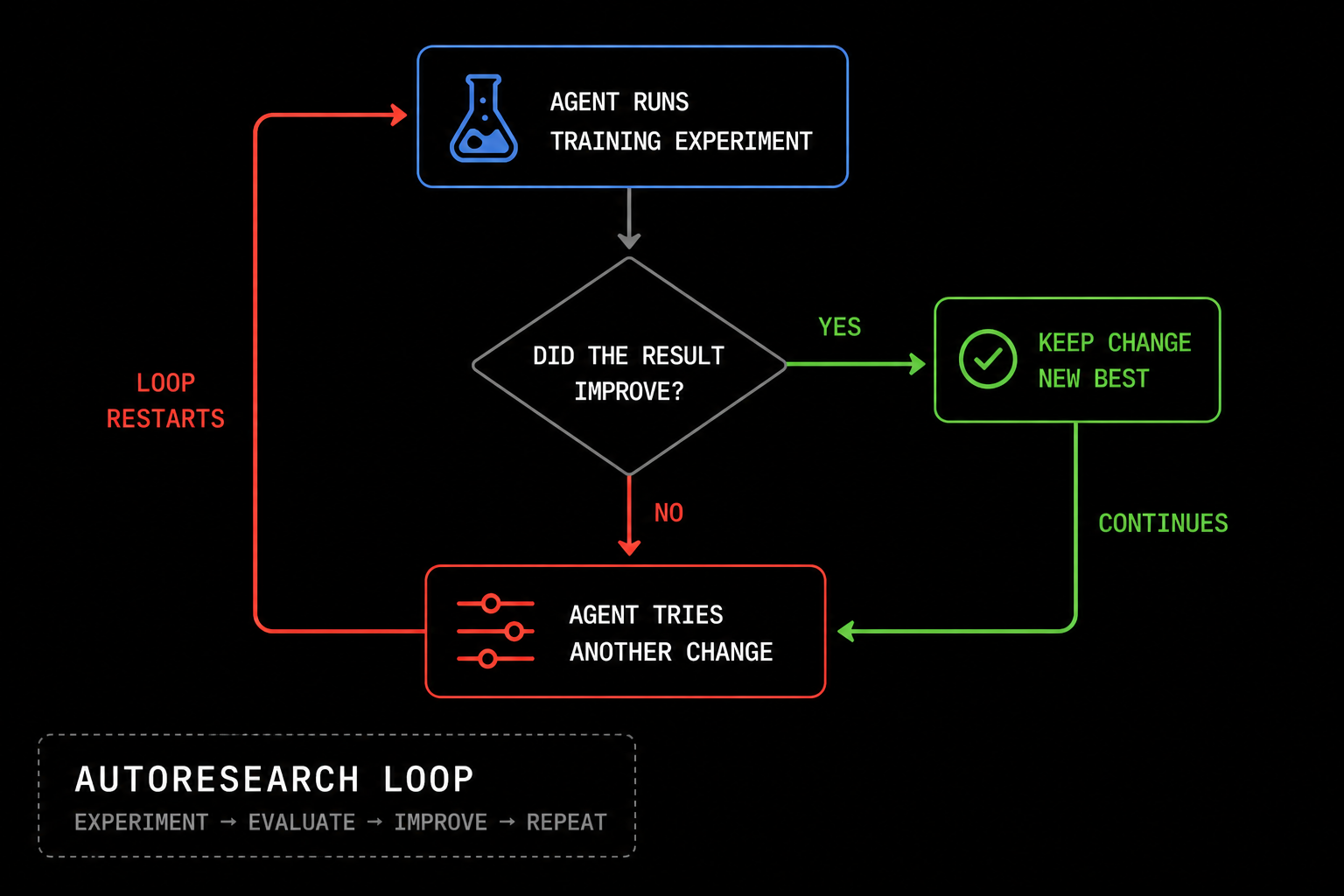
The great Andrej Karpathy famously pioneered a technique called autoreseach, which essentially runs an agent in a loop giving it a task and an objective metric by which it can evaluate its work.
He describes the process like this:
The idea: give an AI agent a small but real LLM training setup and let it experiment autonomously overnight. It modifies the code, trains for 5 minutes, checks if the result improved, keeps or discards, and repeats. You wake up in the morning to a log of experiments and (hopefully) a better model. The training code here is a simplified single-GPU implementation of nanochat. The core idea is that you're not touching any of the Python files like you normally would as a researcher. Instead, you are programming the program.md Markdown files that provide context to the AI agents and set up your autonomous research org. The default program.md in this repo is intentionally kept as a bare bones baseline, though it's obvious how one would iterate on it over time to find the "research org code" that achieves the fastest research progress, how you'd add more agents to the mix, etc. A bit more context on this project is here in this tweet and this tweet.
We created a visual for this process like this:
As you can see, he was able to improve his model substantially after 83 iterations.
Autoresearch is beautiful and simple. But other researchers have automated research in more elaborate ways. As mentioned earlier, DeepMind’s AlphaEvolve scaled test-time compute massively while using standard Gemini models. This required them to generate thousands of LLM samples—which is orders of magnitude more than Karpathy’s 83 iterations visualized above.
Although, we must admit, including “AGI” in the title of this guide is intended to be clickbait, AlphaEvolve arguably gets close. Its results are astounding. Some of its breakthroughs are now implemented in production code at Google today.
AlphaEvolve’s procedure found an algorithm to multiply 4x4 complex-valued matrices using 48 scalar multiplications, improving upon Strassen’s 1969 algorithm that was previously known as the best in this setting. This finding demonstrates a significant advance over our previous work, AlphaTensor, which specialized in matrix multiplication algorithms, and for 4x4 matrices, only found improvements for binary arithmetic.
To investigate AlphaEvolve’s breadth, we applied the system to over 50 open problems in mathematical analysis, geometry, combinatorics and number theory. The system’s flexibility enabled us to set up most experiments in a matter of hours. In roughly 75% of cases, it rediscovered state-of-the-art solutions, to the best of our knowledge.
And in 20% of cases, AlphaEvolve improved the previously best known solutions, making progress on the corresponding open problems. For example, it advanced the kissing number problem. This geometric challenge has fascinated mathematicians for over 300 years and concerns the maximum number of non-overlapping spheres that touch a common unit sphere. AlphaEvolve discovered a configuration of 593 outer spheres and established a new lower bound in 11 dimensions.
Autoresearch works particularly well because you can easily and efficiently quantify the loss in an AI model. Both Autoresearch and AlphaEvolve work well with anything that can quickly generate objective quantifiable results that you can measure an experiment against.
However, churning works for things that are less objective and quantifiable as well.
Ralphing
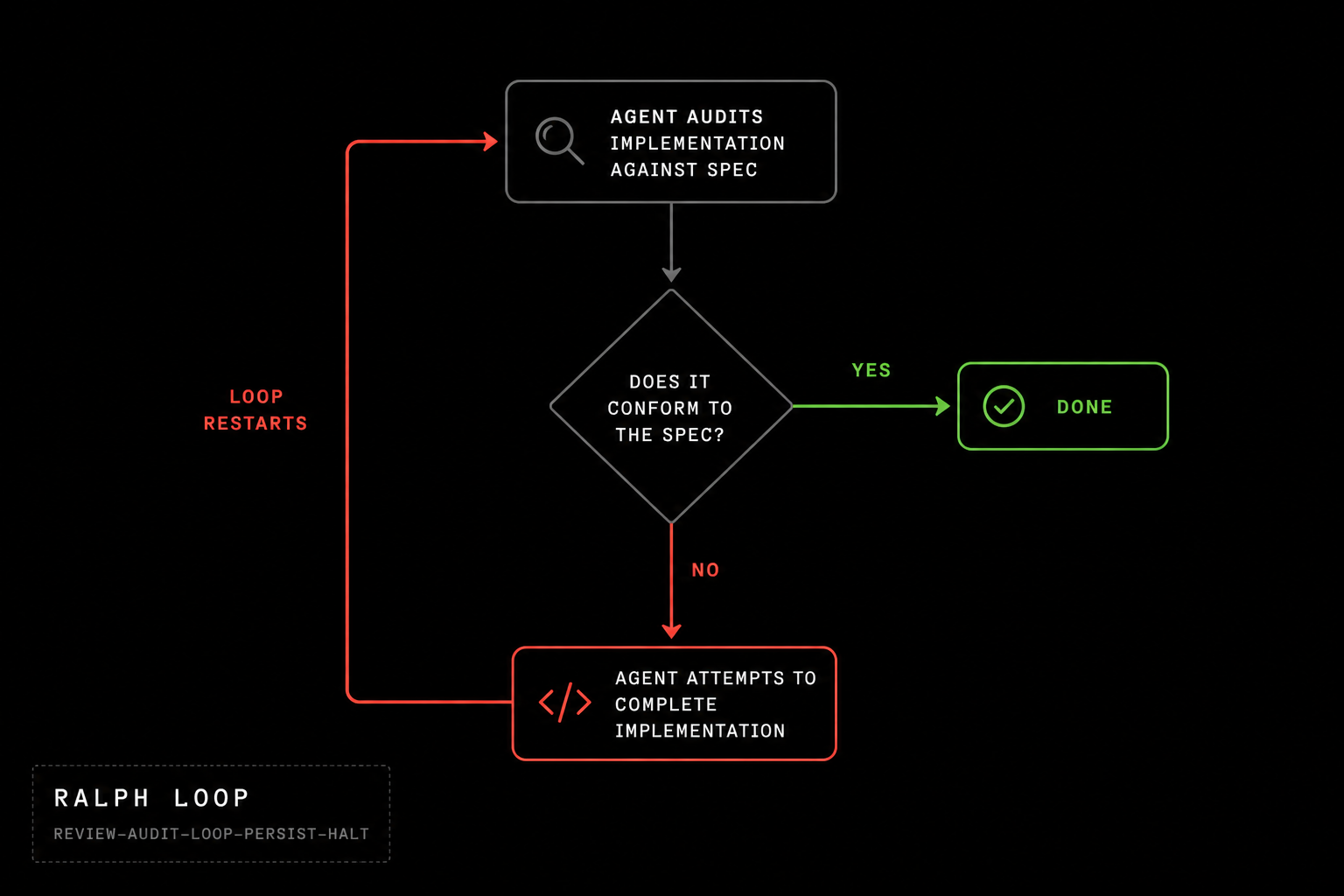
Ralphing, invented by Geoffrey Huntley, is the process of running an agent in a loop so that it can complete a task that is too complicated for it to otherwise complete in a single shot. This is particularly useful when the scope of the project is so large that the agent will get sidetracked by compacting its context numerous times before it is able to achieve its goals.
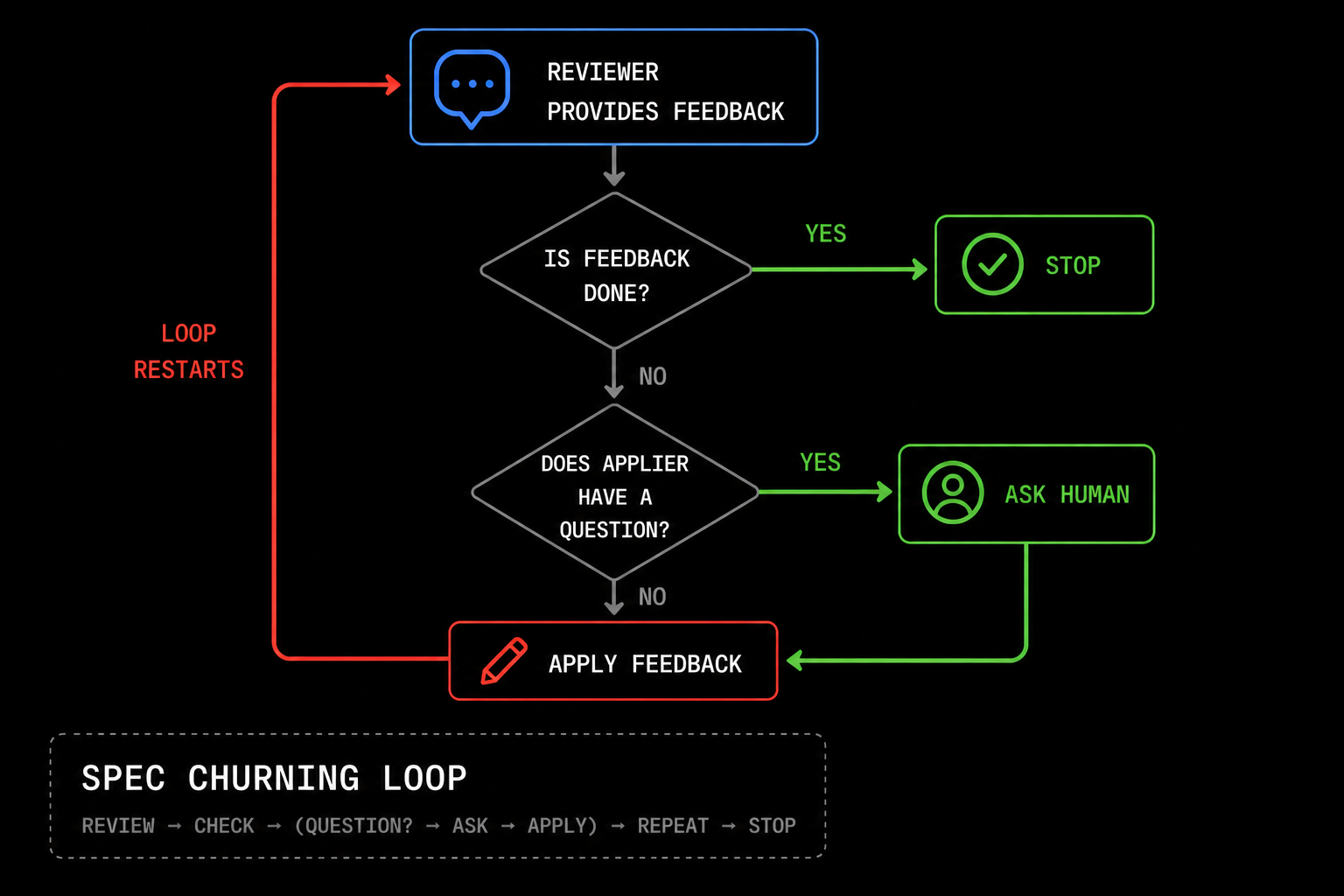
The process itself is simple. You pin your product spec to SPEC.md and you instruct the agent to audit the current implementation of the codebase to see if it fully adheres to the spec, and if not to implement the spec.
At first, the agent will find the spec has not been implemented and so it will take a pass at trying to build it. Since the project is presumably very complex, it won’t succeed on the first try. However, at this point the loop restarts and you instruct it to audit the codebase again. This time it will find it is slightly closer its goal but has more work to do—and it will take another pass at it. After many iterations, the project will be successfully completed.
By properly constructing a prompt that you save to PROMPT.md you can run a ralph loop as simply as
bash
while :; do cat PROMPT.md | claude --dangerously-skip-permissions -p ; done
Building an app correctly is inherently more subjective than optimizing a neural network, so providing metrics for how much this improves an agent’s capability is difficult. But anecdotally this works surprisingly well. Geoffrey Huntley was able to build an entire programming language, Cursed Lang, from scratch using this method.
Specification Churning
At Modular Cloud, we build our product specifications through a method we call “spec churning”. It is essentially iterative refinement with a human-in-the-loop for disambiguation.
Currently, we use GPT 5.5 Pro providing feedback and Claude Code running Opus 4.7 with max effort for applying feedback.
Unlike self-refine, we run this process for anywhere from 10-100+ iterations and only stop when GPT 5.5 Pro has no more suggestions. Contrary to popular belief, this does eventually happen.
This provides remarkable results and allows us to build comprehensive specs covering edge cases that we would simply not consider ourselves.
Keeping a human in-the-loop helps keep the review inline with our intentions. It allows us to put minimal effort into the initial spec, so that we can outsource the process of explaining our ideas to the AI by simply answering a series of pointed questions, a process known as iterative disambiguation.
We then take the specs we have developed and turn them into a working code using a ralph loop. By running this fully automated process, we are able to build robust software end-to-end by only answering questions about the spec.
We will publish more about this specific workflow at a later time and will share our full stack of tooling that helps us automate it. If want to be notified, when this happens, consider subscribing at the bottom of this post.
Even though we haven’t published our full system yet, there is still something you can try today. Take a spec for the software you are building and feed it into ChatGPT Pro at least 10 times. After each iteration, have an AI agent update your spec with the feedback it provided.
Tokenmaxxing
Churning is just a subset of tokenmaxxing techniques. Tokenmaxxing doesn’t have to run in a loop. It can mean that you are asking ChatGPT lots of questions, getting deeper insights into your work. It can also mean that you are using LLMs to handle repetitive tasks like writing emails, that don’t require iterative refinement.
It can entail methods we didn’t have time to cover in the previous section like genetic algorithms, Best-of-N, LLM-as-a-Judge, and more. There is so much research that is waiting to be applied to consumer-side workflows.
The more you scale your AI usage, the more prolific you will become. Right now there is a big arbitrage opportunity in using AI to perform human work at the fraction of the cost.
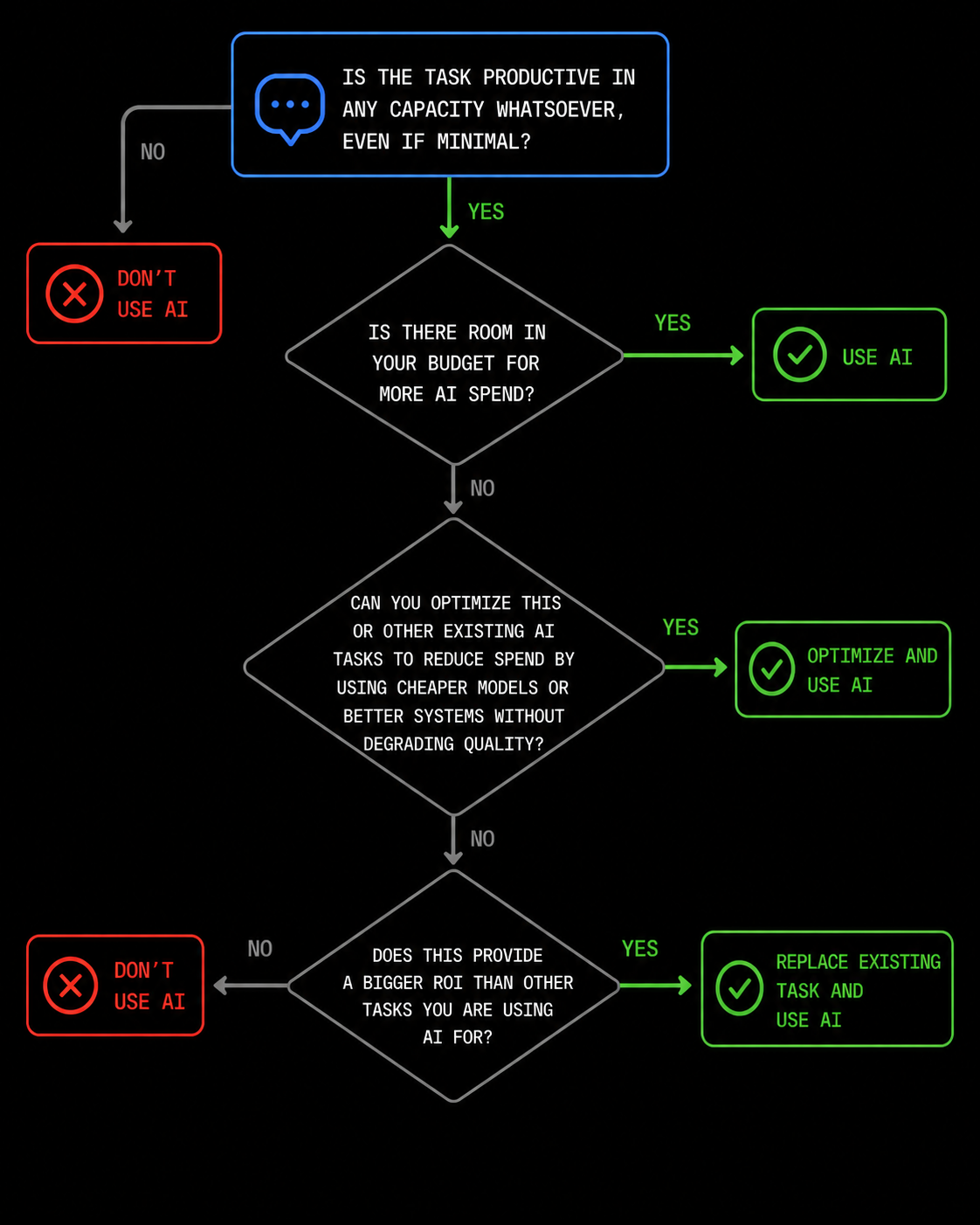
Our general rule of thumb is this: don’t waste tokens by feeding LLMs random or useless prompts, but if you can find any productive way to leverage this technology at all, then you probably should—even if it is inefficient and the benefit is minimal.
You still need to be focused. Don’t spend all day using AI to research goblins, gremlins, and other creatures if your job is software engineering. But you should maximally leverage AI for software engineering related tasks.
What about the cost? Go into debt if you have to (joking! kind of…). You probably should spend within your means, but we suggest scaling your usage to cap out your budget first. Only then should you try to optimize your workflow by substituting cheaper models for tasks they are well suited for—and replacing lower value automations with higher value ones.
You will get better at what you practice. If you practice automating work with AI, your capacity to do so will increase.
Personal Kardashev Scale
Renowned astrophysicist Nikolai Kardashev wrote influential papers on how advanced extraterrestrial civilizations might be detected. His central premise was that more technologically advanced civilizations would likely be capable of harnessing greater amounts of energy. As a result, searches for extraterrestrial intelligence could look for powerful artificial emissions, especially communication signals, and other signs of large-scale energy use.
He famously grouped civilizations into three categories, known as the Kardashev Scale:
A Type I civilization (planetary) is able to access all the energy available on its planet and store it for consumption.
A Type II civilization (stellar) can directly consume a star‘s energy, most likely through the use of a Dyson sphere.
A Type III civilization (galactic) is able to capture all the energy emitted by its galaxy, and every object within it, such as every star, black hole, etc.
To some extent, these categories and labels are arbitrary—but the through line is that each level productively uses vastly more energy than the one preceding it.
This idea was refined further by other great minds. Notably, Carl Sagan introduced intermediary stages, estimating that—at the time of his writing—Earth was a Type 0.7 civilization. In other words, Sagan and others found it useful to think of the Kardashev Scale as more of a gradient than a discrete classification.
But Kardashev was actually not the first research that identified a connection between the level of advancement of a civilization to its energy consumption. An earlier example of this was the work of anthropologist Leslie White, whose views could be summarized as:
Technology is an attempt to solve the problems of survival.
This attempt ultimately means capturing enough energy and diverting it for human needs.
Societies that capture more energy and use it more efficiently have an advantage over other societies.
Therefore, these different societies are more advanced in an evolutionary sense.
Putting all of this together, we can build a useful pragmatic, working definition for what constitutes an advanced civilization. Although this is not a perfect definition, it is a useful heuristic.
⚡️ A civilization is more advanced if it productively harnesses more energy.
But what is a civilization if not a collection of individuals? And what is an individual if not a collection of cells (or neurons)? From a systems perspective, there is no reason why we should think differently about the two.
Therefore, if you want to be the most advanced and powerful version of yourself, maybe you should consider ascending your own personal Kardashev Scale.
Tokenmaxxing is a way to do this. Tokens are a proxy for the productive use of energy. So, what are you waiting for?
Subscribe to Modular Cloud
Get our latest posts delivered to your inbox.
Tokenmaxxing: Brute-Forcing AGI by Scaling Usage | Modular Cloud